表形式データの処理 II: Julia
1. 実習課題について
VSCode の Web版を使って実習課題のコードを書いてください。
• VSCode のリンクはこちら:https://vscode.dev/
各課題につき、
• jlファイルを全て提出してください。
Juliaのターミナで include の方法で、コードを実行してください。
• 重要な出力画面 & グラフは,
注意点:
• グラフをplotする場合、コードの冒頭に、using Plots を挿入してください。
using Plots
2. *事前作業:フォルダーの作成、作業空間の変更
(1) 実習課題用のフォルダーの作成
各自の
• フォルダー名は任意です。(既存のものを使ってもOK)
今回の授業に使う、
VSCode で作業フォルダを開く
• VScode を立ち上げて、
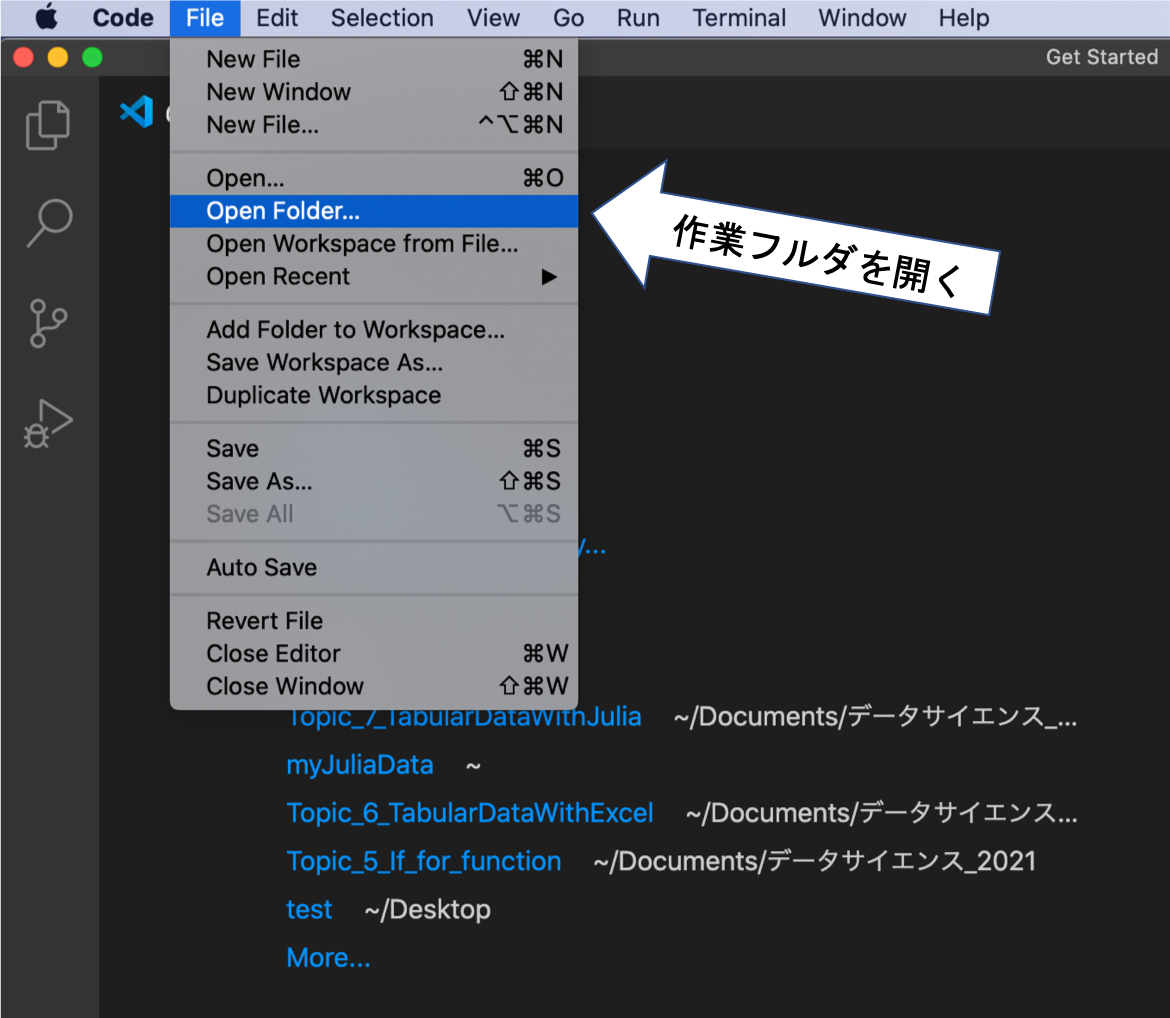
プラグラムのファイルを保存
•
•
データファイルの保存
マウスの
(2) cd で作業空間の変更
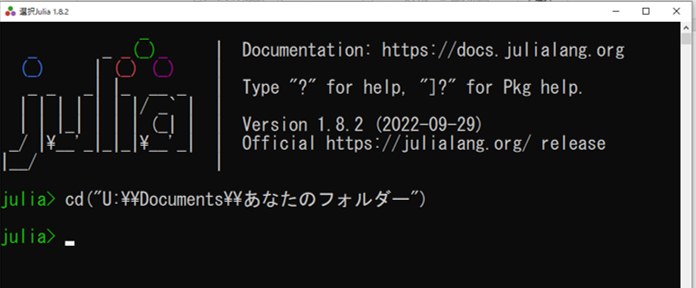
• Julia ターミナル(REPL)を開き、下記のとおりに、
julia> cd("U:\\Documents\\あなたのフォルダー名" )
ターミナルの出力の例:
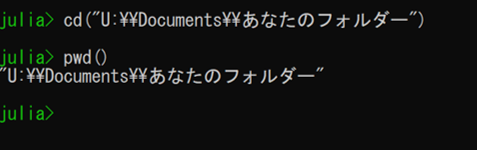
作業空間が確実に変更されたかどうか次のコマンドで確認できる。
julia> pwd()
表示されたフォルダー名が、あなたが作ったものと一致すれば大丈夫です。
例:
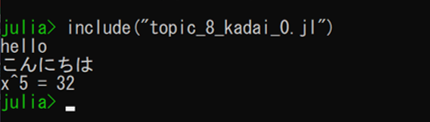
include 関数で .jl ファイルを実行する
• Julia端末で
julia> include("あなたのファイル名.jl" )
実行例:
3. 事前準備:必要なパケージ
今回は、下記のパケージのツールを使います。
• DataFrames
► 表データの処理
• CSV
► CSVファイル関連
• Plots
► グラフの作成
• Statistics
► 平均値、標準偏差の計算
プログラムの冒頭に次のコードを挿入
using DataFrames
using CSV
using Plots
using Statistics
4. Delimiter-separated values
• 区切り文字を用いたデータ形式。
• Delimiter : 区切り文字 または デリミタ とも呼ばれる。
例
10 , 20 , "x文字" , 3.4 , その他
• よく使われている区切り文字:
► Comma コンマ (
► Tab タブ (
► Space スペース (
CSV: Comma-separated values カンマで区切ったデータ形式
• 「カンマ区切り」「コンマ区切り」などとも呼ばれる。
• テキストデータ形式。
• デフォルト拡張子:
• 詳細は こちら(wikipedia)
5. DataFramesとCSVパケージ
• 区切ったデータを
• 外部パケージなので、インストルする必要がある。
• 特徴:
► 列の名前を使って、データの抽出ができる。
► 表示は通常の行列より、綺麗。
► 区切り文字の自動認識。
使い方:
プログラムの最初の行に下記のコードを置く。
using DataFrames
using CSV
ファイルの読み取る:
CSV.read("ファイル名" , DataFrame, header = 列名の行, skipto = データの行,
comment = "コメント文字" ,normalizenames=true)
6. *実習1:CSV ファイルを読み取る
• 次のファイルを右クリックして「名前を付けて保存」で作業フォルダーに保存する。
csv_1.txt ファイルの内容は下記の通りです。
# Example of CSV の例. 数値データは 3行からです。
x, y, z
1, 2, 3
4, 5, 6
7, 8, 9
# 終わり
• 第1行目は説明文言です。読み込まない。
• 第2行目は各列の名前です。
• 最終行は データではない。
要点はこちら:
• データは 3行目から。
• Header ヘッダー は第2行目です。
• コメント文字は # です。
下記のコードを新しい .jl ファイルに書き込む。
• Alt-Enter で実行する。
using DataFrames
using CSV
A = CSV.read("csv_1.txt" , DataFrame, header = 2 , skipto = 3 , comment = "#" , normalizenames=true)
println("データの内容:" )
println(A)
出力
データの内容:
3×3 DataFrame
Row │ x y z
│ Int64 Int64 Int64
─────┼─────────────────────
1 │ 1 2 3
2 │ 4 5 6
3 │ 7 8 9
下記のコードを追加して、データの抽出を行う。
println("\nデータの抽出" )
println("第1列:" )
println(A[:, 1 ])
println("第2行:" )
println(A[2 , :])
出力
データの抽出
第1列:
[1, 4, 7]
第2行:
DataFrameRow
Row │ x y z
│ Int64 Int64 Int64
─────┼─────────────────────
2 │ 4 5 6
sum 関数を用いて、各列と各行の合計値を求める。
println("第3列の合計値" )
println(sum(A[:, 3 ]))
println("第3行の合計値" )
println(sum(A[3 , :]))
出力
第3列の合計値
18
第3行の合計値
24
7. *実習2:列名
先ほどの csv_1.txt ファイルをもう一度使用する。内容はこちら:
# Example of CSV の例. 数値データは 3行からです。
x, y, z
1, 2, 3
4, 5, 6
7, 8, 9
# 終わり
新し jl ファイルで下記のコードを実行する
using DataFrames
using CSV
B = CSV.read("csv_1.txt" , DataFrame, header = 2 , skipto = 3 , comment = "#" , normalizenames=true)
println("データの内容:" )
println(B)
println("
データの抽出" ) # 列の番号ではなくて、列名で呼び出す。
println("x= " , B[:, "x" ]) # 方法1
println("y= " , B[:, :y]) # 方法2
println("z= " , B.z) # 方法3
データの内容:
3×3 DataFrame
Row │ x y z
│ Int64 Int64 Int64
─────┼─────────────────────
1 │ 1 2 3
2 │ 4 5 6
3 │ 7 8 9
データの抽出
x= [1, 4, 7]
y= [2, 5, 8]
z= [3, 6, 9]
8. *実習3: 甲府の気温
下記、甲府2019年の気象データのァイルを「名前を付けて保存」で作業フォルダに保存
データの元は 気象庁 です。
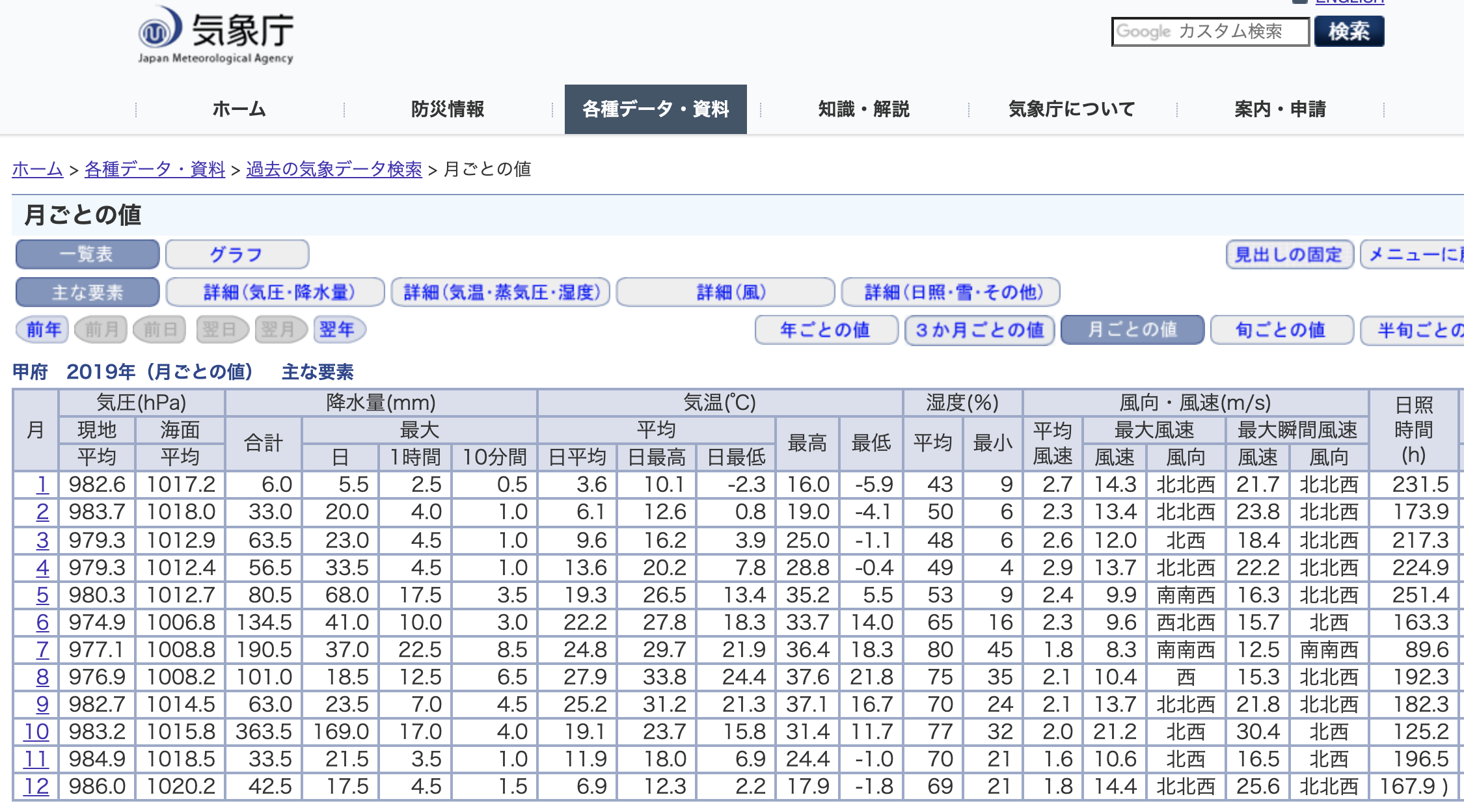
ファイルの内容の一部はこちら:
甲府 2019年(月ごとの値) 主な要素
単位 hPa mm 度 度 度 % m/s h
月 気圧 降水量 気温 最高気温 最低気温 湿度 風速 日照時間
1 982.6 6 3.6 10.1 -2.3 43 2.7 231.5
2 983.7 33 6.1 12.6 0.8 50 2.3 173.9
⋮
12 986 42.5 6.9 12.3 2.2 69 1.8 167.9
• 区切り文字は タブ です。
• ヘッダー行(列名)は 3行目
• 数値データは 4行目から
新しいファイルに下記コードを実行する。
using DataFrames
using CSV
using Plots
using Statistics
B = CSV.read("kofu2019.txt" , DataFrame, header = 3 , skipto = 4 , comment = "#" , normalizenames=true)
println("甲府の天気:" )
println(B)
出力
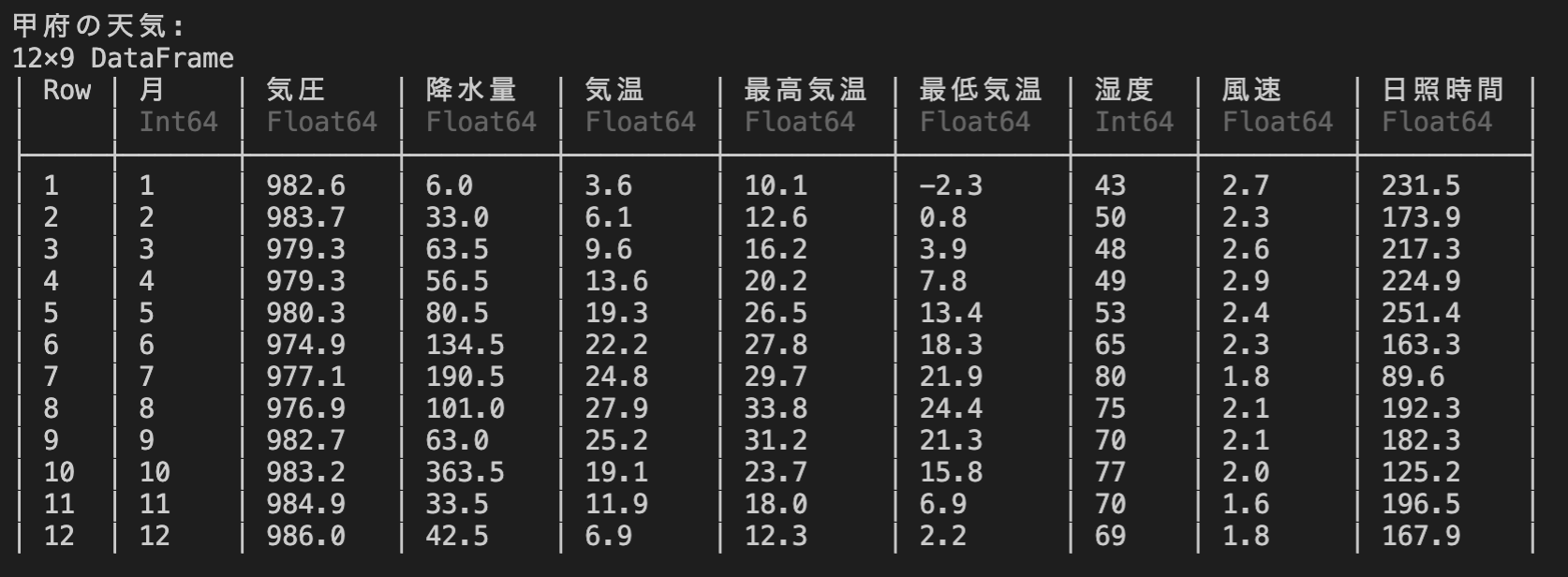
下記のコードを追加して、未完成の部分を完成させる。
•
•
•
•
# 統計パケージを使って平均値と標準偏差を算出する
println("-" ^20 )
println("気温の年間平均 = " , mean(B.気温))
println("気温の年間標準偏差 = " , std(B.気温))
println("降水量の最大値 = " , maximum(B.降水量))
println("気圧の最小値 = " , minimum(❓))
出力:
--------------------
気温の年間平均 = 15.85
気温の年間標準偏差 = 8.31466393570037
降水量の最大値 = 363.5
気圧の最小値 = 974.9
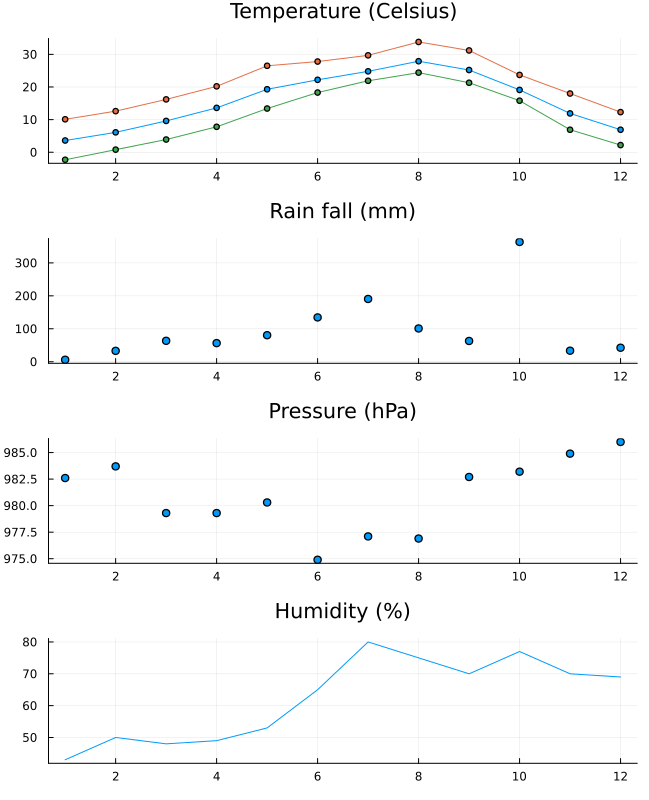
下記のコードを追加して、グラフを描く
plot(B.月, B.気温, marker = 5 , markershape = :square, label="Ave" )
plot!(B.月, B.最高気温, marker = 5 ,markershape = :circle, label = "Max" )
plot!(B.月, B.最低気温, marker = 5 , markershape = :utriangle, label = "Min" )
plot!(xlabel = "Month" , ylabel = "degree" , title = "Kofu's annual temperature (2019)" )
plot!(xticks = (1:1 :12 ))
出力:
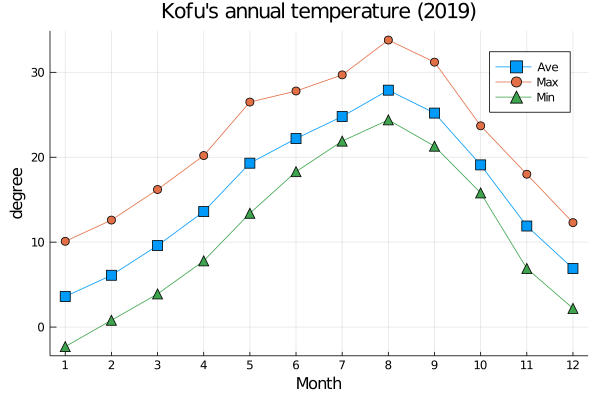
下記のコードを追加して、x軸の表示を任意の文字にする。
Mon = ["Jan" , "Feb" , "Mar" , "Apr" , "May" , "Jun" , "Jul" , "Apr" , "Sep" , "Oct" , "Nov" , "Dec" ]
plot!(xticks = (1:1 :12 , Mon))
display(plot!())#plot! が最後の行じゃなかったら、displayの関数に入れて、強制的に表示をさせる。
savefig("mykofutemp.png" ) #保存。 plotly の場合、この指令は不要です。
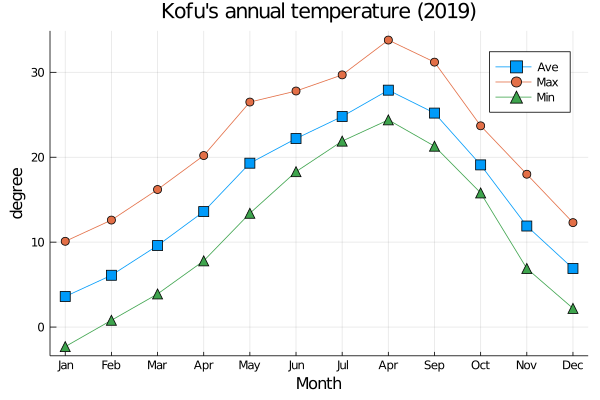
9. *実習4: 甲府の気象データ
• 先ほどのファイルを Save で保存して、そしてもう一度 Save as で別ファイル名で保存してください。
• 下記のコードを参考にして、4つの気象データを plot する。
using DataFrames
using CSV
using Plots
B = CSV.read("kofu2019.txt" , DataFrame, header = 3 , skipto = 4 , comment = "#" , normalizenames=true)
#自由にスタイルを変えてみる。
Temperature = plot(B.月, B.気温, marker = 3 )
plot!(B.月, B.最高気温, marker = 3 )
plot!(B.月, B.最低気温, marker = 3 )
plot!(title = "Temperature (Celsius)" , legend = false, xticks = (2:2 :12 ))
#主な追加部分:
Rain = scatter(B.月, B.降水量, legend = false, title = "Rain fall (mm)" ,xticks = (2:2 :12 ))
Pressure = scatter(B.月, B.気圧, title = "Pressure (hPa)" ,xticks = (2:2 :12 ), legend = false)
Humidity = plot(B.月, B.湿度, title = "Humidity (%)" , xticks = (2:2 :12 ), legend = false)
#4つのグラフを一斉に描く
plot(Temperature, Rain, Pressure, Humidity, layout = (2,2 ))
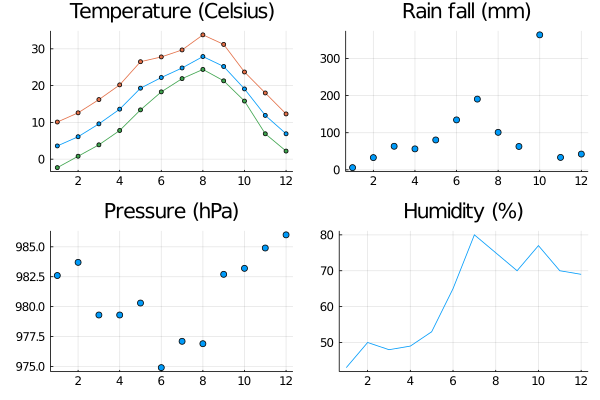
最後は任意のファイ名で下記のコードを実行してグラフを保存する。
例:
savefig("mykofu_meteorological_data.png" )
10. *実習5: 甲府の気象データ2
例
参考資料:共通資料の「plot も簡易マニュアル」